Segmentacja obiektów
W tym scenariuszu musieliśmy stworzyć system Automatycznego Rozpoznawania Tablic Rejestracyjnych (Automatic License Plate Recognition - ALPR) do monitorowania miejskiego, szczególnie w celu monitorowania pasów dla autobusów. W tym dokumencie skupimy się na pierwszej fazie procesu, która obejmuje przetwarzanie danych, ale także na szkoleniu i ocenie modelu segmentacji w celu wyodrębnienia tablic rejestracyjnych z oryginalnych nagrań.
Konfiguracja środowiska CGC
Zacznijmy od mocy obliczeniowej potrzebnej do tego zadania. Chcemy szybko iterować, więc NVIDIA A100 będzie najlepszym wyborem. Jednak jeśli Twój zestaw danych nie przekracza 24GB, nadal będziesz w stanie przeprowadzić trening bez partii na A5000. Powinieneś to wziąć pod uwagę, wybierając najlepszy stosunek ceny do prędkości.
W ramach tego projektu utworzyliśmy środowisko PyTorch z GPU A100 oraz zamontowaliśmy dysk o pojemności 100GB.
cgc volume create your_volume -s 100
cgc compute create nvidia-pytorch -n your_name -g 1 -gt A100 -m 8 -v your_volume
Przygotowanie danych
Jak zawsze zaczynamy od nieprzetworzonych nagrań wideo. Filmy powinny być w formacie najlepiej odpowiadającym narzędziom, których używasz. My głównie polegamy na opencv i ffmpeg do przetwarzania wideo, więc nasze pliki używają kodeka h264 w kontenerze mp4.
Nasz zestaw danych zawiera filmy z kilku kamer rozmieszczonych w mieście, gdzie widoczne są kilka pasy. Do treningu sieci neuronowej potrzebujemy obrazów (klatek) zamiast wideo (klatek sklejonych razem).
Przycinanie klatek
Interesują nas tylko buspasy, więc pierwszą rzeczą do zrobienia było przycięcie klatek, aby każdy obraz pokazywał tylko jeden pas w danym momencie.

Etykietowanie
Kiedy mamy już wszystkie klatki zapisane, pora na najlepszą część! Ręczne etykietowanie...

Na szczęście mamy narzędzie w CGC, które to ułatwia - Label Studio.
Aby go użyć, po prostu je utwórz:
cgc compute create label-studio -n your_name
Następnie możesz zalogować się do interfejsu internetowego dostarczanego przez to narzędzie. Wszystkie niezbędne informacje, takie jak adres URL dostępu i AppToken, można znaleźć tutaj:
cgc compute list -d
Login: admin@localhost
Hasło: AppToken dostarczony przez cgc compute list -d
Początkowo musimy utworzyć nowy projekt, nazwać go i przekazać zdjęcia jako dane. Następnie wybieramy jedną z dostępnych konfiguracji etykietowania:
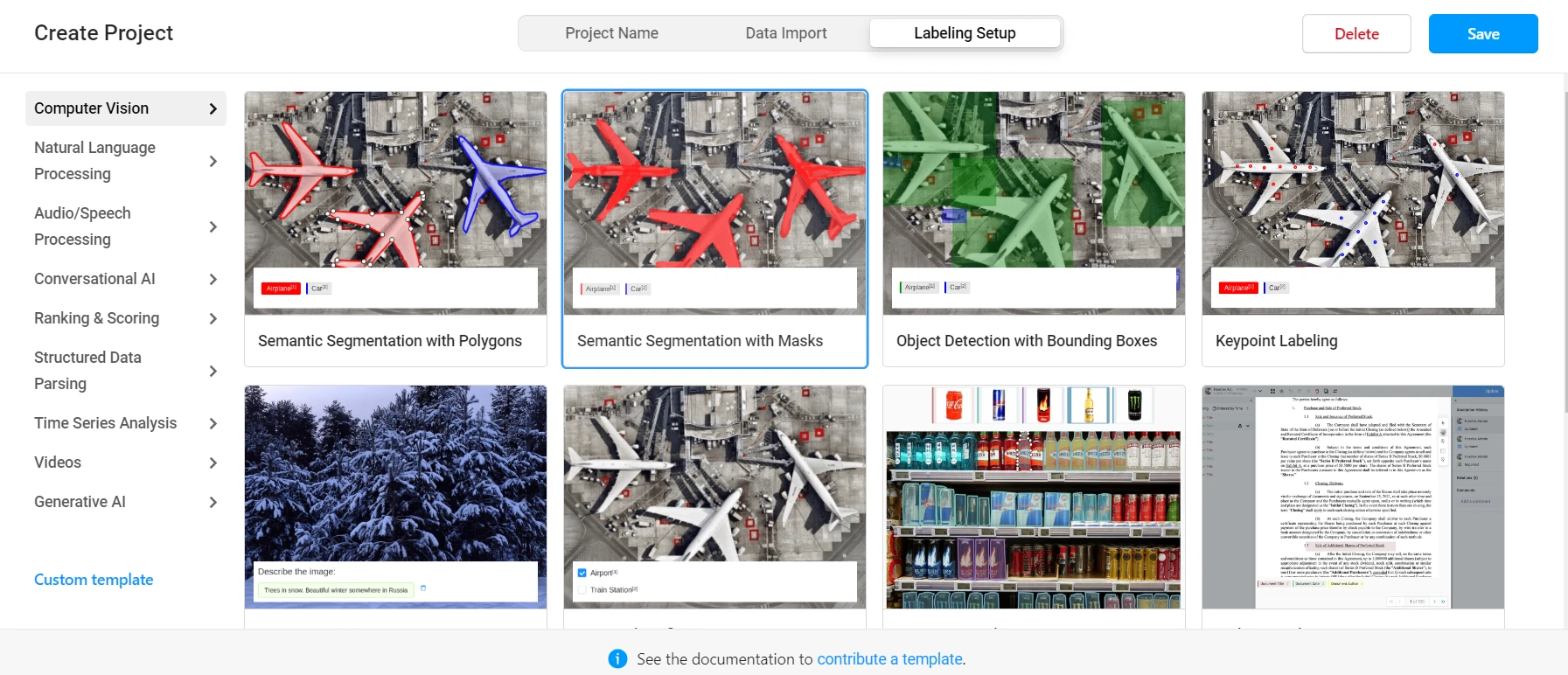
Istnieje konfiguracja dla różnych zadań, ale tym razem użyjemy Object Detection with Bounding Boxes.
Label Studio obsługuje tylko przesyłanie 100 obrazów na raz, jeśli masz większy zestaw danych, przesyłaj je partiami.
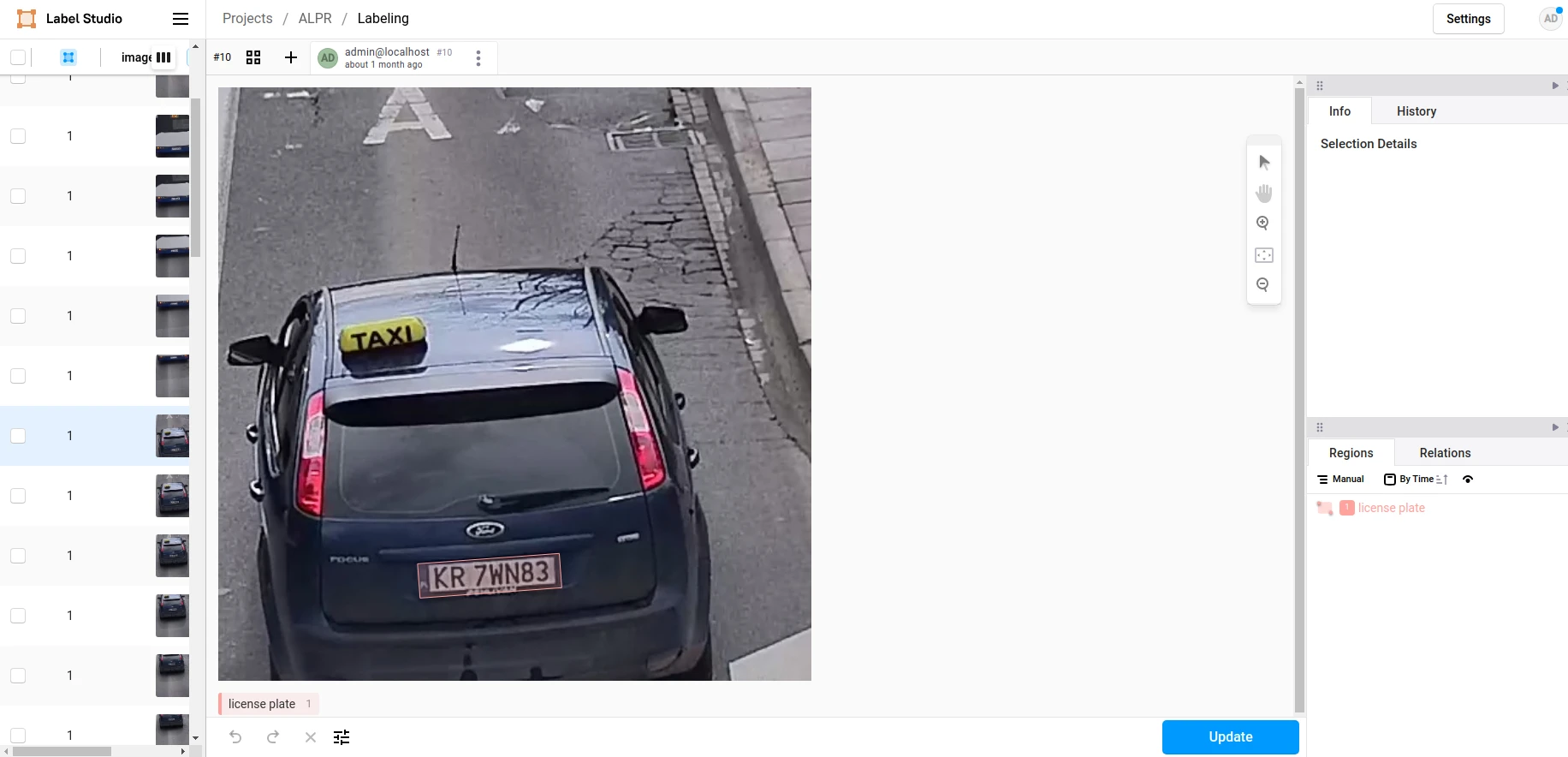
Po utworzeniu projektu możesz utworzyć dowolne etykiety, których potrzebujesz, w naszym przypadku potrzebna była tylko jedna etykieta - tablica rejestracyjna. Oznaczyliśmy każdy obraz prostokątnymi ramkami wokół tablic.
Eksportowanie danych
Po zakończeniu etykietowania możesz wyeksportować wyniki na swój dysk, w dowolnym formacie, który Ci odpowiada. My wybraliśmy format danych COCO.
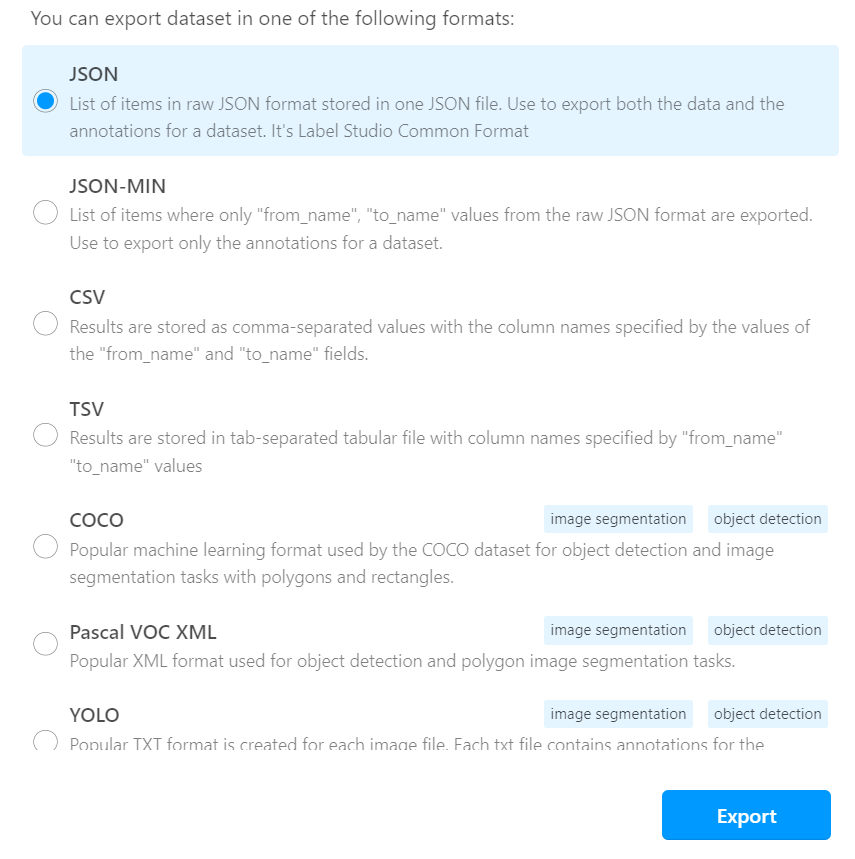
Po eksporcie otrzymasz folder obrazów i plikiem JSON z wynikami. Obrazy mają inne nazwy niż te przesłane, ale ich nie zmieniaj, ponieważ te nazwy są już zapisane w pliku wynikowym. To w tym pliku zostaną umieszczone wszystkie Twoje etykiety, w zależności od wybranego formatu danych. W COCO wygląda to tak:

A każda etykieta wygląda tak:

Trening
Kiedy już oznaczymy nasze dane, czas na ich przetwarzanie i załadowanie do modelu.
Ładowanie danych
Zanim rozpoczniemy trening, musimy stworzyć zbiór danych i dataloader, który będzie dostarczał obrazy do naszego modelu. Kod użyty do przetwarzania danych i treningu modelu można znaleźć na naszym gitlabie.
Sieci neuronowe oczekują, że dane wejściowe będą w określonym formacie, w tym przypadku dokumentacja PyTorch jasno pokazuje, jaki format jest oczekiwany:

Aby dopasować się do tego formatu, stworzyliśmy klasę Dataset InstanceSegmentationCocoDataset, która znajduje się w plate_segmentation/datasets.py.
root = "/workspace/alpr/"
dataset = alpr.plate_segmentation.datasets.InstanceSegmentationCocoDataset(root = root,
images_path="data/object_detection/labeled/gopro_short/images/",
coco_labels_path="data/object_detection/labeled/gopro_short/annotations/result.json",
transforms=alpr.ai_utils.transforms.get_transform(train=True)
)
Trening segmentacji
Do segmentacji wykorzystaliśmy transfer learning. Model bazowy to fasterrcnn_resnet50_fpn_v2 z pytorch. Ponieważ nie mieliśmy dużo danych, naszą najlepszą opcją było użycie domyślnych wag i trenowanie tylko ostatnich kilku warstw. Aby predyktor pasował do naszego zadania, musiał zostać zamieniony na nowy, który przewiduje tylko 2 klasy - tablica i tło.
def get_model_instance_segmentation(num_classes: int, default: bool):
if default:
model = torchvision.models.detection.fasterrcnn_resnet50_fpn_v2(
weights=None, weights_backbone="DEFAULT", trainable_backbone_layers=3
)
else:
model = torchvision.models.detection.fasterrcnn_resnet50_fpn_v2(weights=None)
num_classes = 2 # class license-plate + background
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
num_classes = 2
model = segmentation.get_model_instance_segmentation(num_classes, default=True)
num_epochs = 50
engine = AlprSetupTraining(model, dataset, batch_size=2, train_split=0.8)
engine.train(num_epochs=num_epochs, save_path=root+"fasterrcnn_resnet50_fpn_v2.pt")
Inferencja i przycinanie tablic
Teraz, gdy mamy wagi dla naszego wytrenowanego modelu segmentacji, możemy rozpocząć inferencję. Aby rozpoznać znaki na tablicach, musimy przekazać je do modelu OCR (opisanego w osobnym samouczku). Ale potrzebujemy tylko tablicy rejestracyjnej, nie całego obrazu. Aby przyciąć przychodzące obrazy, po prostu wczytujemy je do sieci neuronowej.
# we begin with unprocessed photos
images = []
root = "/workspace/alpr/"
imgs_path = "frames/"
images_nr = 100
for file in list(sorted(os.listdir(root + imgs_path)))[:images_nr+1]:
try:
images.append(Image.open(root+imgs_path+file).convert("RGB"))
except Exception as err:
print(f"Cant open {file}, {err}")
Sieć segmentacji w akcji:
# setup the cropping of license plate
# we will use our trained model, but you can use whatever model you want as long as its detector predicts 2 classes - plates and background
model = segmentation.get_model_instance_segmentation(num_classes=2, default=True)
cropper = segmentation.PlateCropper(model=model, images=images)
cropper.load_state_dict(path_to_weights=root+"fasterrcnn_resnet50_fpn_v2.pt")
plates, scores = cropper.crop_plates(score_threshold=0.9995)
Pokazuje tablice wykryte na kolejnych klatkach:

I to wszystko!