Vision API
CGC nie wystawia surowych portów RTSP ingress dla workloadów Vision API. Vision API może publikować przetworzone strumienie przez RTSP, ale serwer RTSP/SFU musi być dostępny jako zewnętrzny endpoint TCP. Dla produkcyjnego streamingu RTSP użytkownik powinien dostarczyć własny serwer SFU, na przykład MediaMTX, poza CGC albo w infrastrukturze, w której można wystawić prawdziwy port RTSP TCP.
Zewnętrzny SFU musi nasłuchiwać na ruch RTSP publish/ingest, najczęściej na 8554/TCP, oraz musi akceptować połączenia wychodzące z workloadów CGC. Vision API działa jako klient RTSP i wypycha przetworzony stream do tego SFU; nie wystawia własnego portu RTSP wewnątrz CGC.
Przegląd Rozwiązania
API Vision jest przeznaczone do zapewnienia kompleksowego rozwiązania dla zadań związanych z widzeniem komputerowym. Łączy ono przetwarzanie wstępne, inferencję, postprocessing i serwowanie w jednym żądaniu do endpointu. Wykorzystuje Triton jako źródło inferencji, w połączeniu z operacjami przetwarzania obrazu i wideo przyspieszonymi dzięki GPU . Do serwowania strumieni używa przyspieszonych przez GPU Serwerów Gstreamer.
Kluczowe funkcje:
- Plik obrazu jako wejście, detekcja, przetworzony plik obrazu jako wyjście
- Plik wideo jako wejście, detekcja, przetworzony plik wideo jako wyjście
- Strumień jako wejście, detekcja, przetworzony strumień RTSP jako wyjście
Jak uruchomić
Ponieważ Triton jest źródłem inferencji, najpierw musisz upewnić się, że jest on skonfigurowany i włączony Triton.
Na ten moment Vision API akceptuje tylko standardowe wyjście modelu detekcji - [x1, x2, y1, y2, score, class_1, class_2 ..], jeżeli z jakiegoś powodu twój model ma inny output, API do nie przyjmie.
API Vision jest dostępne jako zasób obliczeniowy i wymaga różnych zasobów w zależności od wybranych operacji przetwarzania i rozdzielczości źródła. Aplikacja zawsze wymaga GPU, które obsługuje operacje przetwarzania obrazu. Najlepszym wyborem będzie A5000. Na początek zalecamy 1,5 rdzenia CPU i 1,5 GB RAM na każde wideo/strumień, który będziesz przetwarzać. Te wartości mogą wzrosnąć, gdy dodasz operacje lub użyjesz źródeł o wyższej rozdzielczości.
Wymagania konfiguracji SFU
Vision API używa zewnętrznego serwera SFU/RTSP, na przykład MediaMTX, do wystawiania strumienia wyjściowego. Aplikacja nie hostuje publicznego endpointu RTSP w CGC. Zamiast tego przetwarza klatki i wypycha wynikowy stream do skonfigurowanego SFU za pomocą GStreamer rtspclientsink po TCP.
SFU musi spełniać następujące wymagania:
- Musi być osiągalny sieciowo z workloadów CGC.
- Musi nasłuchiwać na prawdziwym porcie RTSP TCP ingest, najczęściej
8554/TCP. - Jego firewall/security group musi pozwalać na połączenia przychodzące z adresów egress CGC albo z publicznego internetu, zależnie od konfiguracji.
- Musi pozwalać na publikowanie RTSP do skonfigurowanej ścieżki, na przykład
/vision-api/<stream_id>. - Jeżeli włączone jest uwierzytelnianie, dane dostępowe muszą zgadzać się z
SFU_AUTH_USERiSFU_AUTH_TOKEN. - Klienci odbierają stream wyjściowy z SFU, nie z ingressu Vision API w CGC.
Podczas tworzenia zasobu obliczeniowego skonfiguruj następujące zmienne środowiskowe:
SFU_INTERNAL_SERVER_URL: bazowy URL RTSP używany przez Vision API do publikowania przetworzonych streamów do SFU, np.rtsp://sfu.example.com:8554SFU_EXTERNAL_SERVER_URL: bazowy URL RTSP zwracany klientom do oglądania streamów, np.rtsp://sfu.example.com:8554SFU_AUTH_USER: nazwa użytkownika do uwierzytelniania SFUSFU_AUTH_TOKEN: hasło/token do uwierzytelniania SFU
W większości konfiguracji z zewnętrznym SFU SFU_INTERNAL_SERVER_URL i SFU_EXTERNAL_SERVER_URL mogą wskazywać na ten sam bazowy URL RTSP.
Aby uruchomić instancję, użyj następującej komendy:
cgc compute create --name vision-api -c 8 -m 12 -g 1 -gt A5000 vision-api \
-e SFU_INTERNAL_SERVER_URL="rtsp://sfu.example.com:8554" \
-e SFU_EXTERNAL_SERVER_URL="rtsp://sfu.example.com:8554" \
-e SFU_AUTH_USER="your-auth-username" \
-e SFU_AUTH_TOKEN="your-auth-token"
Konfiguracja wolumenu dla statystyk licznika obiektów
Jeśli planujesz używać funkcji licznika obiektów i chcesz zapisywać statystyki do plików, musisz utworzyć i zamontować wolumin:
# Utwórz wolumen dla statystyk (dostosuj rozmiar według potrzeb)
cgc volume create -s 2 stats
# Zamontuj wolumen do zasobu obliczeniowego Vision API
cgc volume mount stats -t vision-api -fp /app/stats
Po inicjalizacji możesz uzyskać dostęp do Swagger, aby zobaczyć wszystkie endpointy pod adresem:
https://vision-api.<namespace>.cgc-waw-01.comtegra.cloud/docs
Domyślna konfiguracja
APP_TOKEN: Token aplikacji dla Computer Vision API. Jest ustawiony na specyficzny dla CGCapp_token, który otrzymujesz po utworzeniu zasobu obliczeniowego.SFU_INTERNAL_SERVER_URL: Wewnętrzny URL RTSP dla serwera MediaMTX (wymagany)SFU_EXTERNAL_SERVER_URL: Zewnętrzny URL RTSP dla dostępu klienta (wymagany)SFU_AUTH_USER: Nazwa użytkownika do uwierzytelniania MediaMTX (opcjonalna, może być pusta)SFU_AUTH_TOKEN: Token uwierzytelniania dla MediaMTX (wymagany do bezpiecznego streamingu)STREAM_STATS_DIR: Ścieżka katalogu do zapisywania statystyk licznika obiektów (opcjonalna, domyślnie "stats")
Jak używać
Każdy endpoint będzie wymagał od Ciebie przekazania tokenu aplikacji jako źródła autoryzacji. Jest to ten sam token aplikacji, który możesz zobaczyć przy użyciu:
cgc compute list -d
Istnieją 3 sposoby korzystania z Vision API w zależności od pożądanego wejścia i wyjścia. Pierwsze 2, w których możesz uzyskać plik jako wyjście, będą miały podobny sposób użycia.
Najpierw prześlij plik na
/image/upload lub /video/upload
i otrzymasz uuid, który reprezentuje źródło. Następnie możesz go uwzględnić w żądaniu do
image/to-image lub video/to-video.
Zwróć uwagę na treść żądania:
{
"source_file_uuid": "98ada9eb-daf6-4ee4-b4be-9fab7abdf619",
"tritonServer": {
"triton_url": "triton",
"infer_model_name": "yolov8n",
"version": "1"
},
"inference": {
"confidence_threshold": 0.25,
"iou_threshold": 0.45
},
"postprocess": {
"bbox": {
"apply": true,
"rectangle_color": "default",
"text_color": "default",
"rectangle_thickness": 2,
"text_size": 0.5,
"text_thickness": 2,
"include_text": false
},
"blur": {
"apply": false,
"blur_intensity": [99, 99],
"classes": "auto",
"partial_blur_classes": null
},
"pose": {
"apply": true,
"keypoints": {
"apply": true,
"keypoint_color": [0, 165, 255],
"line_color": [255, 165, 0],
"radius": 5,
"line_thickness": 2
},
"pose_classifier": {
"apply": true,
"slope_threshold": 40,
"fall_detector": {
"apply": false,
"alert_threshold": 2
}
}
}
},
"output_format": "jpg"
}
Tutaj możesz wpisać otrzymane uuid i zmienić wszystko, co chcesz w inferencji i postprocessingu. Po wypełnieniu treści żądania, wyślij je i poczekaj. Gdy przetwarzanie się zakończy, otrzymasz plik zawierający przetworzony obraz lub wideo.
Trzeci endpoint, który zwraca strumień RTSP, będzie wymagał podobnego żądania, ale natychmiast zwróci adres URL strumienia. Endpoint zwraca adresy URL strumienia skonfigurowanego SFU. Jeżeli SFU jest zewnętrzny, klient odbiera stream bezpośrednio z tego SFU.
Gdy nie potrzebujesz już strumienia, możesz go usunąć, przekazując stream_id do /stream/delete-stream.
Dostępny jest również endpoint informacyjny info/get-models, który pobiera modele dostępne na Triton z informacjami o nich.
Dodatkowo dostępny jest endpoint statystyk /statistics/export, który umożliwia eksport danych licznika obiektów zebranych podczas streamingu. Ten endpoint przyjmuje stream_id i format (CSV lub XLSX) do pobrania pliku statystyk.
Jeśli wolisz używać API nie przez Swagger, możesz wysyłać żądania w taki sposób:
curl -X 'POST' \
'https://<appname>.<namespace>.cgc-waw-01.comtegra.cloud/video/to-stream' \
-H 'accept: application/json' \
-H 'app-token: 8d23ae613a4e46119f4d52cb25e8b551' \
-H 'Content-Type: application/json' \
-d '{
"source_file_uuid": "ac839d89-14c7-4116-b5d8-30c34c714971",
"tritonServer": {
"triton_url": "triton",
...
}
Wstawiając token aplikacji w nagłówku i parametry w body.
Szczegółowe informacje
Opcjonalne parametry aplikacji
Dodatkowe opcjonalne parametry, które możesz przekazać do polecenia create w CLI:
STREAM_STATS_DIR- Ścieżka katalogu do zapisywania statystyk licznika obiektów. Jeśli nie zostanie podana, funkcje statystyk muszą być wyłączone. Musi być ścieżką zamontowanego woluminu (np./app/stats).
Parametry żądania
Treść żądania ma kilka sekcji, zaczynając od sekcji Triton, gdzie musimy określić hosta Triton. W przypadku CGC, Triton postawiony w tym samym namespace będzie dostępny pod nazwą kontenera, na przykład: triton. Dodatkowo wybieramy model, którego chcemy użyć, jego wersję oraz triton_request_concurrency, który jest dostępny wyłącznie dla endpointu wideo i wskazuje, ile klientów będzie jednocześnie zapytaniać Triton. Jest to przykład parametru, który wpływa zarówno na czas wykonania zapytania, jak i zużycie zasobów, co należy wziąć pod uwagę.
Sekcja inferencji dotyczy typowych tematów dla inferencji modelu:
- confidence threshold
- intersection over union threshold
Endpoint stream/to-stream zawiera również parametry enkodera (encoder), które określają sposób kodowania strumienia wyjściowego:
| Parametr | Domyślna wartość | Opis | Uwagi |
|---|---|---|---|
bitrate | 800000 | Przepływność strumienia wyjściowego, mierzona w bitach na sekundę (bps). | Wyższa wartość poprawia jakość, ale zwiększa zużycie pasma. |
width | "default" | Szerokość strumienia wideo w pikselach. | Jeśli ustawiono "default", zostanie użyta oryginalna szerokość strumienia. |
height | "default" | Wysokość strumienia wideo w pikselach. | Jeśli ustawiono "default", zostanie użyta oryginalna wysokość strumienia. |
Jeśli podano własną szerokość/wysokość, obraz zostanie skalowany z opcjonalnym dodaniem wypełnienia, aby zachować proporcje.
Sekcja postprocessingu dotyczy wszystkiego, co dzieje się po uzyskaniu wyników inferencji. Możemy wybrać nakładanie ramek w miejscach, gdzie model wykrył obiekty, rozmywanie tych obszarów lub użycie filtra Kalmana do poprawy ciągłości detekcji.
Konfiguracja Trackera
Oprócz opcji postprocessingu, takich jak nakładanie ramek, rozmazywanie obszarów lub używanie filtrów Kalmana, użytkownicy mogą modyfikować parametry trackera, aby zoptymalizować precyzję detekcji i poprawić funkcjonalność różnych funkcji, takich jak klasyfikacja pozycji, zliczanie obiektów oraz filtracja Kalmanem dla zapewnienia ciągłości detekcji. Eksperymentując z tymi parametrami, użytkownicy mogą dostosować swoje aplikacje, aby uzyskać lepszą dokładność i niezawodność.
Dostępne parametry do dostosowania:
| Parametr | Domyślna wartość | Opis | Uwagi |
|---|---|---|---|
track_activation_threshold | 0.25 | Próg pewności detekcji dla aktywacji śledzenia. | Zwiększenie tej wartości poprawia dokładność i stabilność, ale może pomijać prawidłowe detekcje. Zmniejszenie zwiększa kompletność, ale ryzykuje wprowadzenie szumu i niestabilności. |
lost_track_buffer | 30 | Liczba klatek buforowanych po utracie śledzenia. | Zwiększenie tej wartości zmniejsza fragmentację śledzenia lub znikanie z powodu krótkich przerw w detekcji. |
minimum_matching_threshold | 0.8 | Próg dopasowania śledzeń z detekcjami. | Zwiększenie tej wartości poprawia dokładność, ale ryzykuje fragmentacją. Zmniejszenie poprawia kompletność, ale zwiększa ryzyko fałszywych pozytywów. |
frame_rate | "auto" | Liczba klatek na sekundę wideo. Jeśli ustawiona na "auto," liczba klatek na sekundę jest automatycznie wyodrębniana ze źródła. | Ustaw stałą liczbę klatek, jeśli liczba klatek na sekundę źródła jest zmienna lub nieznana. |
minimum_consecutive_frames | 1 | Liczba kolejnych klatek, które obiekt musi być śledzony, zanim zostanie uznany za prawidłowy. | Zwiększenie tej wartości zapobiega tworzeniu przypadkowych śledzeń z fałszywej lub podwójnej detekcji, ale ryzykuje pomijanie krótszych śledzeń. |
Część informacji o parametrach została pobrana z oficjalnej dokumentacji biblioteki Supervision.
Estymacja Pozy
Estymację pozy można skonfigurować przez ustawienie pose na true podczas używania modeli "Pose".
Sekcja estymacji pozy zawiera następujący zestaw parametrów:
| Parametr | Domyślna wartość | Opis | Uwagi |
|---|---|---|---|
pose.apply | false | Włącza lub wyłącza funkcję estymacji pozycji. | Ustaw na true, aby aktywować estymację pozycji. Wymagane podczas korzystania z modeli "Pose Estimation". |
keypoints.apply | true | Włącza lub wyłącza rysowanie punktów reprezentujących stawy ciała. | Punkty kluczowe reprezentują wykryte stawy. |
keypoints.keypoint_color | [0, 165, 255] | Ustawia kolor BGR dla punktów kluczowych. | [0, 165, 255] dla żółtego. |
keypoints.line_color | [255, 165, 0] | Ustawia kolor BGR dla linii łączących punkty kluczowe. | [255, 165, 0] dla niebieskiego. |
keypoints.radius | 5 | Określa promień punktów kluczowych w pikselach. | Większe wartości zwiększają widoczność punktów kluczowych na klatce obrazu. |
keypoints.line_thickness | 2 | Określa grubość linii łączących punkty kluczowe w pikselach. | Grubsze linie poprawiają widoczność przy wyższych rozdzielczościach klatek obrazu. |
pose_classifier.apply | false | Włącza lub wyłącza klasyfikację pozycji. | Dostępne pozycje: Standing (stojąca) lub Laying (leżąca). |
pose_classifier.slope_threshold | 40 | Ustawia kąt nachylenia do klasyfikacji pozycji jako leżącej. | Dostosuj wartość, aby precyzyjnie dostroić dokładność klasyfikacji pozycji. |
fall_detector.apply | false | Włącza lub wyłącza funkcję wykrywania upadków. | Alerty wykrywania upadków mogą być przydatne w aplikacjach o krytycznym znaczeniu dla bezpieczeństwa. |
fall_detector.alert_threshold | 2 | Określa próg czasowy (w sekundach) dla uruchomienia alertu upadku. | Niższe wartości zwiększają czułość wykrywania upadków; dostosuj w zależności od wymagań. Domyślnie alert o upadku zostanie wywołany, jeśli osoba leży przez dwie sekundy. |
Podczas korzystania z modeli do estymacji pozycji, należy ustawić parametr pose na true, aby zapewnić prawidłowe działanie.
Obecnie funkcja estymacji pozy obsługuje tylko modele YOLO-pose z 17 punktami kluczowymi w formacie COCO.
Liczenie Obiektów
Funkcja Liczenia Obiektów (object_counter) umożliwia zliczanie określonych klas obiektów, które poruszają się przez linię podziału w klatce wideo. Jest to szczególnie przydatne w scenariuszach takich jak monitorowanie ruchu drogowego, liczenie ludzi lub przedmiotów oraz analiza wzorców ruchu.
Poniższe parametry są dostępne do konfiguracji funkcji Liczenia Obiektów:
| Parametr | Domyślna wartość | Opis | Uwagi |
|---|---|---|---|
apply | true | Włącza lub wyłącza funkcję liczenia obiektów. | Ustaw true, aby aktywować funkcję liczenia obiektów. |
line_type | "axis" | Określa typ linii używanej do liczenia obiektów. Wybierz "axis" dla linii poziomej/pionowej lub "custom" dla linii zdefiniowanej ręcznie. | Jeśli wybierzesz "axis", musisz określić oś (axis), na której linia będzie rysowana. Jeśli wybierzesz "custom", określ parametry line_start i line_end. |
axis | "x" | Określa oś, na której rysowana jest linia dzieląca. Używane tylko, gdy line_type="axis". | Wybierz "x" dla linii pionowej lub "y" dla linii poziomej. |
position | "1/2" | Określa pozycję linii dzielącej na wybranej osi. Używane tylko, gdy line_type="axis". | Akceptuje liczbę całkowitą (pozycję w pikselach) lub ułamek jako ciąg znaków (np. "1/2" dla środka klatki). |
line_start | [null, null] | Definiuje punkt początkowy linii niestandardowej. Używane tylko, gdy line_type="custom". | Podaj współrzędne punktu początkowego linii w formacie [x, y]. Dowiedz się więcej... |
line_end | [null, null] | Definiuje punkt końcowy linii niestandardowej. Używane tylko, gdy line_type="custom". | Podaj współrzędne punktu końcowego linii w formacie [x, y]. Dowiedz się więcej... |
class_id_map | {"person": 0} | Mapuje nazwy klas obiektów na odpowiadające im identyfikatory klas. | Co najmniej jedna klasa musi zostać określona. Jeśli nie jesteś pewien identyfikatorów klas, skorzystaj z aplikacji Netron. |
draw_counts | true | Wyświetla liczbę obiektów po obu stronach linii dzielącej. | Pokazuje, ile obiektów z każdej klasy przekroczyło linię w obu kierunkach. |
draw_dividing_line | true | Rysuje linię dzielącą na klatce wideo. | Przydatne do wizualnego wskazania, gdzie obiekty są liczone. |
line_color | [255, 255, 255] | Ustawia kolor linii dzielącej w formacie BGR. | [255, 255, 255] oznacza białą linię. |
line_thickness | 2 | Określa grubość linii dzielącej. | Dostosuj w zależności od rozdzielczości klatki wideo, aby linia była bardziej widoczna. |
Jak określić współrzędne dla parametrów line_start i line_end
Podczas definiowania punktu początkowego i końcowego linii niestandardowej należy podać współrzędne w formacie [x, y]. Współrzędne te reprezentują pozycje w siatce klatki wideo lub obrazu. Przykład działania:
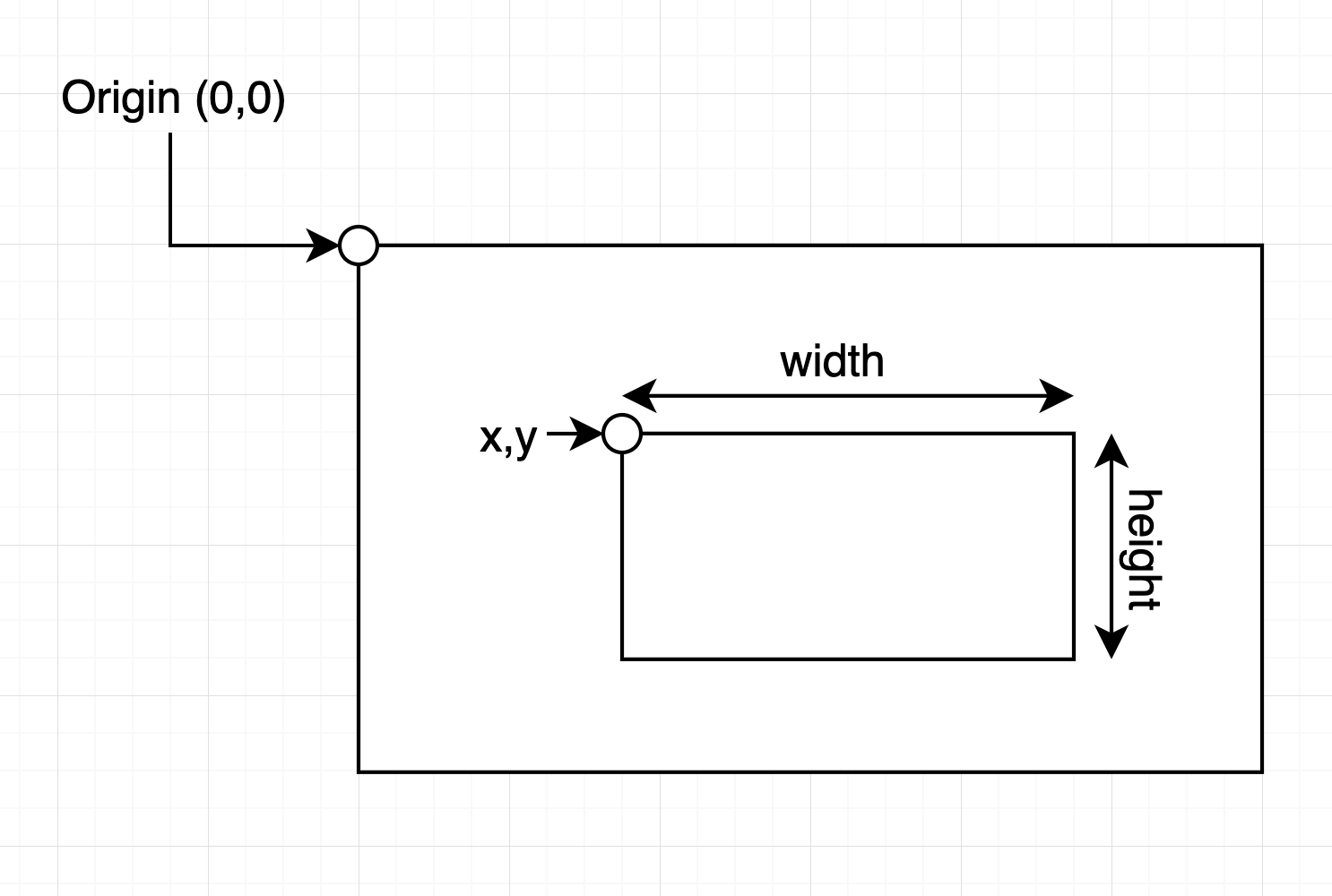
- Lewy górny róg: Lewy górny róg klatki to punkt
(0, 0). - Oś pozioma (X): Współrzędna
xzwiększa się w miarę przesuwania się w prawo wzdłuż klatki, co odpowiada szerokości klatki. - Oś pionowa (Y): Współrzędna
yzwiększa się w miarę przesuwania się w dół klatki, co odpowiada wysokości klatki.
Na przykład:
line_start: Określa punkt początkowy linii. Na przykład[0, 1080]umieści początek w lewym dolnym rogu klatki o rozdzielczości 1920x1080.line_end: Określa punkt końcowy linii. Na przykład[1920, 0]umieści koniec w prawym górnym rogu klatki o rozdzielczości 1920x1080.
Rozszerzona konfiguracja rozmycia
Funkcja rozmycia została rozszerzona o nowe możliwości dla bardziej precyzyjnej kontroli rozmycia:
| Parametr | Domyślna wartość | Opis | Uwagi |
|---|---|---|---|
apply | false | Włącza lub wyłącza funkcję rozmycia. | Ustaw na true, aby aktywować rozmycie. |
blur_intensity | [99, 99] | Określa rozmiar jądra rozmycia jako [szerokość, wysokość]. | Obie wartości muszą być liczbami nieparzystymi między 1-100. Wyższe wartości tworzą silniejsze efekty rozmycia. |
classes | "auto" | Określa, które klasy obiektów mają być rozmyte. | Użyj "auto", aby rozmyć wszystkie wykryte klasy, lub podaj listę ID klas jak [0, 1, 2]. |
partial_blur_classes | 1.0 | Konfiguracja częściowego rozmycia w obrębie ramek ograniczających. | Opcjonalny obiekt konfiguracyjny dla zaawansowanej kontroli rozmycia w określonych regionach wykrytych obiektów. |
Konfiguracja częściowego rozmycia:
Kiedy podano partial_blur_classes, powinien zawierać:
blur_region: Która część ramki ograniczającej ma być rozmyta ("top","bottom","left","right","center")blur_percentage: Jaki procent ramki ma być rozmyty (między 0.1 a 1.0)
Przykład konfiguracji częściowego rozmycia:
"partial_blur_classes": {
"blur_region": "bottom",
"blur_percentage": 0.3
}
Statystyki i eksport danych
Vision API zawiera teraz kompleksowy system statystyk dla danych liczenia obiektów:
| Funkcja | Opis | Wymagania |
|---|---|---|
write_statistics | Umożliwia zapisywanie statystyk licznika obiektów do plików. | Wymaga zamontowanego wolumenu w ścieżce /app/stats. Ustaw na true w konfiguracji object_counter. |
| Eksport statystyk | Eksportuj zebrane statystyki w formacie CSV lub XLSX. | Użyj endpointu /statistics/export z stream_id i żądanym formatem. |
| Śledzenie w czasie rzeczywistym | Statystyki są zapisywane w czasie rzeczywistym, gdy obiekty przekraczają linie liczenia. | Dane zawierają znaczniki czasu, typy obiektów, kierunki przekraczania i liczby. |
Aby włączyć zbieranie statystyk:
- Zamontuj wolumin do przechowywania statystyk (zobacz instrukcje konfiguracji wolumenu powyżej)
- Ustaw
write_statistics: truew konfiguracjiobject_counter - Użyj endpointu
/statistics/export, aby pobrać zebrane dane
Każda opcja ma swoje podopcje, które modyfikują ich zachowanie. Ponownie, ważne jest, aby pamiętać, że im więcej postprocessingu dodamy, tym dłużej potrwa zapytanie i tym więcej zasobów zostanie zużytych. Wszystkie opcje poza ramkami są domyślnie wyłączone. W przypadku kolorów domyślna opcja - "default" oznacza, że każda wykryta klasa będzie miała przypisany inny losowy kolor. Jeśli chcesz użyć określonego koloru, możesz podać go w formie tablicy RGB - np.: [255, 0, 0], wtedy KAŻDA klasa będzie miała ten kolor. Może to być przydatne, gdy masz tylko jedną lub kilka klas.
Na koniec mamy format wyjścia. Obecnie zaimplementowany jest tylko jeden format, więc domyślne ustawienie nie powinno być zmieniane.
Strumienie RTSP
Endpoint stream/to-stream przetwarza stream wejściowy i publikuje przetworzony wynik do skonfigurowanego SFU.
Przepływ:
stream wejściowy -> Vision API w CGC -> publikacja RTSP do zewnętrznego SFU -> klient odbiera stream z SFU
Vision API nie wymaga wystawionego portu RTSP. Aplikacja otwiera połączenie wychodzące TCP do SFU_INTERNAL_SERVER_URL i publikuje tam stream. Zwrócony external_stream_url powinien być używany przez klientów do odbioru streamu z SFU.
CGC ingress nie może być używany jako publiczny endpoint RTSP dla odtwarzania rtsp://.... Jeżeli klient wymaga wyjścia w formacie RTSP, musi dostarczyć SFU/serwer RTSP z osiągalnym, nasłuchującym portem RTSP TCP.
Błędy i rozwiązywanie problemów
Ta sekcja zawiera informacje o tym, gdzie zwracane są błędy podczas przetwarzania i jak je interpretować. Zrozumienie komunikatów o błędach i ich przyczyn pozwoli szybko rozwiązać problemy i zapewnić płynne działanie systemu.
Lokalizacja błędów
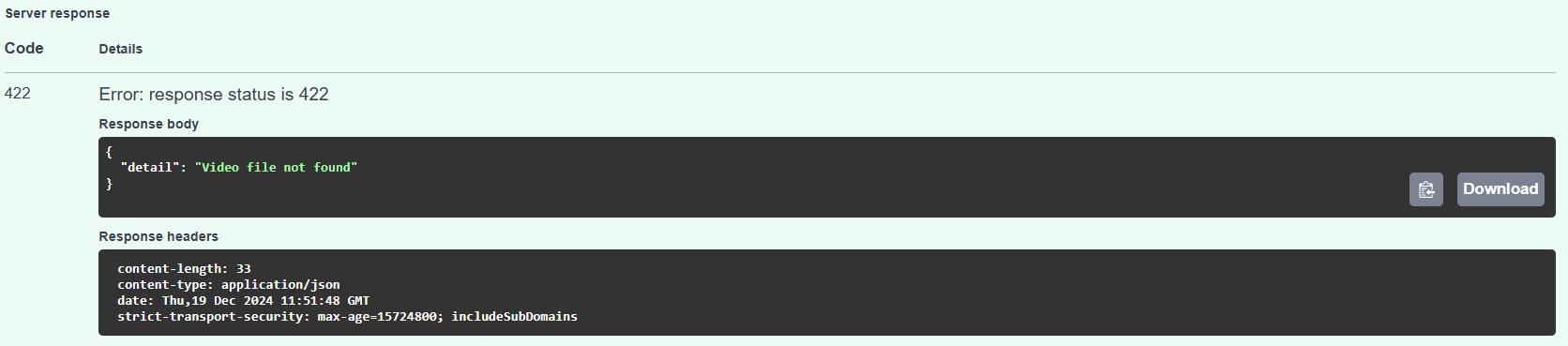
Większość błędów będzie widoczna w Responses > Server Response. Szczegółowe informacje o błędach można znaleźć w części Response Body odpowiedzi serwera.
Na przykład błąd dotyczący nieistniejącego pliku wideo (który może wystąpić, gdy parametr source_file_uuid jest nieprawidłowy) będzie wyglądał następująco:
Błędy w parametrach
W przypadku problemów z dostarczonymi parametrami w odpowiedzi znajdą się szczegółowe komunikaty o tym, co poszło nie tak. Poniżej znajduje się przykład takiego błędu:
{
"detail": [
{
"type": "value_error",
"loc": [
"body",
"postprocess",
"pose",
"pose_classifier",
"slope_threshold"
],
"msg": "Value error, Slope threshold must be between 0 and 90 degrees",
"input": 150,
"ctx": {
"error": {}
},
"url": "https://errors.pydantic.dev/2.10/v/value_error"
}
]
}
W tym przykładzie:
- Opis błędu: Parametr
slope_thresholdzostał podany z nieprawidłową wartością (150). - Przyczyna: Prawidłowy zakres wartości dla
slope_thresholdto od 0 do 90 stopni. - Rozwiązanie: Zaktualizuj wartość
slope_threshold, aby mieściła się w dopuszczalnym zakresie.
Odpowiedź z błędem zawiera:
- Typ: Wskazuje typ błędu, np.
value_error. - Lokalizacja (
loc): Pokazuje, gdzie w hierarchii parametrów wystąpił błąd. - Wiadomość (
msg): Zawiera dokładny opis błędu. - Wprowadzone dane (
input): Wyświetla podaną nieprawidłową wartość. - URL: Link do dokumentacji z dodatkowymi szczegółami dotyczącymi typu błędu.
Błąd modelu do estymacji pozycji
Jeśli pojawi się następujący błąd:
RuntimeError encountered during pose estimation: shape '[1, 17, 3]' is invalid for input of size 0. Are you sure you are using a pose estimation model?
Oznacza to, że funkcja estymacji pozycji została włączona, ale używany model nie obsługuje estymacji pozycji.
Rozwiązanie:
- Zmień model na taki, który obsługuje estymację pozycji (zobacz jak skonfigurować).
- Alternatywnie wyłącz funkcję
pose, ustawiając parametrapplynafalsew sekcji parametrów dotyczącej pozycji.
Błędy konfiguracji SFU
Przy streamingu opartym na SFU możesz napotkać specyficzne błędy konfiguracji:
Błąd uwierzytelniania SFU:
SFU_AUTH_TOKEN environment variable must be set for authenticated streaming
Rozwiązanie: Upewnij się, że podajesz SFU_AUTH_TOKEN podczas tworzenia zasobu obliczeniowego.
Błąd konfiguracji SFU:
SFU_INTERNAL_SERVER_URL environment variable must be set for streaming
SFU_EXTERNAL_SERVER_URL environment variable must be set for client access
Rozwiązanie: Podaj obie zmienne środowiskowe SFU URL z prawidłowymi URL RTSP (muszą zaczynać się od rtsp://).
Błąd woluminu statystyk: Jeśli statystyki licznika obiektów są włączone, ale wolumen nie jest zamontowany, możesz zobaczyć błędy związane z zapisem plików. Rozwiązanie: Upewnij się, że utworzyłeś i zamontowałeś wolumin statystyk zgodnie z opisem w sekcji konfiguracji.
Punkt końcowy stream/to-stream zwraca teraz zarówno wewnętrzne, jak i zewnętrzne URL strumieni. Jeśli zwrócone URL nie działają, możesz rozwiązać problemy, sprawdzając logi i potencjalne błędy za pomocą następującego polecenia:
cgc logs <vision-api-compute-resource-name>
Na przykład dla powyższej konfiguracji polecenie wyglądałoby następująco:
cgc logs vision-api
To polecenie zapewni szczegółowe logi zasobu obliczeniowego Vision API, pomagając użytkownikom w diagnozowaniu i rozwiązywaniu problemów związanych ze streamingiem SFU.
Ponieważ endpoint streamingu działa w środowisku wieloprocesowym, błędy mogą nie pojawić się natychmiast i może być potrzebny pewien czas, aby pojawiły się w CGC.